Livongo has been partnering for years with Kleiner Perkins’ Silicon Valley Fellows program. Dhruv joined Livongo as a backend software engineering intern during the summer of 2019. At the time of his internship, Dhruv was a rising junior at the University of Pennsylvania’s Jerome Fisher Program in Management in Technology. This post is about Dhruv’s summer project, which was to launch an Elasticsearch cluster to quickly and scalably search through our recruitable population.
Motivation: A Faster Registration Flow
Livongo uses more than a dozen personal identifying data points in providing our services-–information such as a member’s name, birthdate, insurance plan, and zip code. In the past, new members would have to input all of this data manually during the signup process, which could be tedious. But, as Dave discussed in his post, Livongo already has access to much of this information through the data streams that clients provide us to engage our eligible population, also called our recruitable population. We knew that some companies have seen double or even triple-digit improvements in conversion rate by reducing the length of their forms, so the tech team was interested in experimenting with connecting new members to their existing information at sign-up to fast-track them through the process.
Current Approach
In our initial implementation, we would pull the key identifiers of our recruitable population from our Redshift data warehouse every morning as part of our ETL Jenkins job. We would then clean, filter, and upload the data into a MySQL table, which our registration flow could query through our backend APIs. Now, when new members register, we need only collect a few unique identifiers that can be used to search the MySQL database and retrieve their corresponding “recruitable” data. This data can be used to auto answer many of the registration fields. The result was a smart sign-up process that made it more convenient for new members to take advantage of their Livongo benefits.
The Problem
We soon found that using MySQL created other issues. First, the ETL stage responsible for populating the table took an awfully long time to run–around an hour–and caused MySQL performance degradation across our entire server. At Livongo’s current size and rate of growth, we were concerned that this overhead would soon become intractable. Second, MySQL didn’t have native support for the sophisticated queries we wanted to run against the data, which led to fragile search queries and server latency. For example, we wanted to use fuzzy queries to help link members to their data even if they’ve made typos or used a nickname–like inputting “Chris” or “Chirstoper” instead of “Christopher”. But to implement this in MySQL, we had to brute force search through the database and calculate the Levenshtein distance for each record, which is an extremely expensive operation. We needed an alternative to MySQL that was more scalable and a better fit for our use case.
New Proposal
We found a compelling option in Elasticsearch, a NoSQL, RESTful, distributed document storage system based on Apache Lucene. Elasticsearch works by storing documents (JSON objects) in structures called inverted indices that make them easily searchable. Then, it distributes those indices across multiple nodes in a cluster to spread traffic. Elasticsearch seemed like a promising replacement for MySQL–it was supposedly faster, due to this inverted index structure, and more useful, due to better native search functionality. My project was to work with various groups within the tech team to deploy an Elasticsearch cluster and develop the appropriate ETL stages and backend APIs to make it a viable replacement for our MySQL implementation.
The Basic Mechanics of Searching in Elasticsearch
The fundamental unit of datastore in Elasticsearch is the document, which is simply a JSON object. It’s analogous to a row or record in a MySQL table. Here’s a representative snippet of the kind of document Livongo might want to store:
{ ... "first_name": "John", "last_name": "Doe", "conditions": [ "DIABETES", "HYPERTENSION" ], "zipcode": "12345-6789", "client_code": "LVGO", "health_questions": [ { "name": "diabetes_type", "value": 2 } ] ... }
This JSON is also called a source document. When we upload a document into Elasticsearch (also called indexing), it doesn’t store only the source. It breaks up the document and its fields into parse tokens, based on rules specified by a mapping, and stores those tokens in a structure called an inverted index. The inverted index maps the tokens to the documents in which they appear. When a query is executed, the query string is split into tokens using the same rules, and then that set of tokens is transformed into a set of documents through the inverted index. So, we can see how the way documents are tokenized has a big impact on the speed and functionality available to APIs who wish to search the cluster.
To make an optimal mapping, we started by thinking about what search operations we wanted to support on our cluster, based on input from Livongo Data Science. We then worked backwards to develop a mapping that was optimized for those functions. For example, one operation relied on suffix matching (i.e. “ends with xyz”). Since Elasticsearch can only efficiently search for prefixes, we had our mapping store the forward and reverse versions of our tokens. That way, we could efficiently search for suffixes using prefix operations.
How Livongo Uses Elasticsearch
Now that we understand how Elasticsearch works, we can further discuss how Livongo has adapted the technology for our use.
Cluster Architecture
We host our Elasticsearch cluster on an AWS EC2 instance. It currently contains one node partitioned into 5 shards. As we acquire more clients, we intend to increase the number of nodes and pair it with intelligent data routing to improve performance. Below is a diagram which shows, at a high level, how our cluster fits into our backend infrastructure.
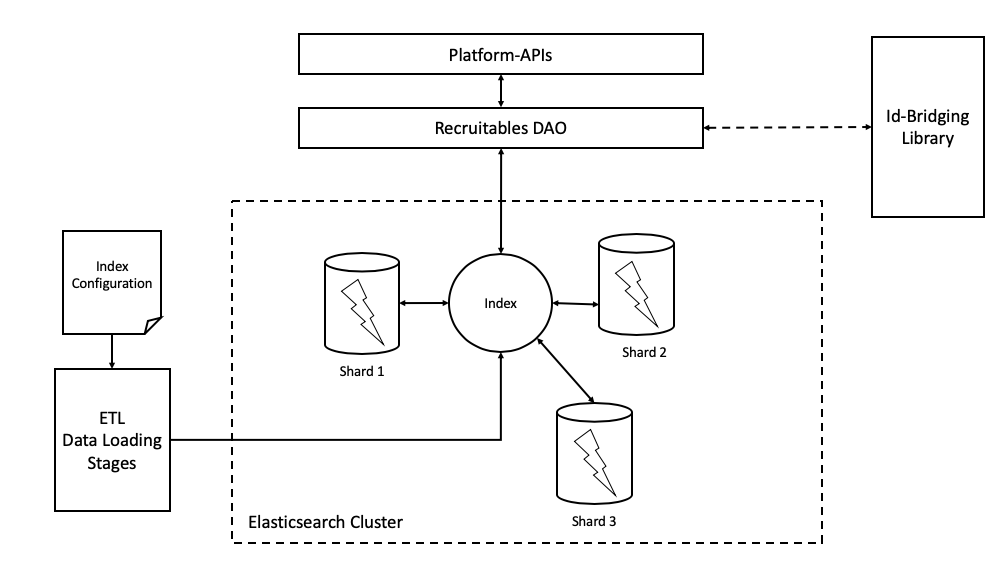
Our Elasticsearch cluster is populated by an ETL data loading stage using a mapping defined by a configuration file. Our backend-apis can query the cluster through a DAO that uses a library to turn internal search requests into Elasticsearch queries. This process is discussed in more detail later in the post.
Aliasing
Because of some meta features of our data–such as its shelf-life and expected usage–we decided to create a new index every day and reinitialize it with data from our clients, rather than keep updating a single, persistent index. We believe this one-directional approach is more efficient and maintainable. To keep things simple for our backend-APIs, we only query an aliased endpoint that persists from day-to-day, but is mapped to the most recent index everytime the ETL is run. This alias-switching can be done transactionally, leading to zero downtime.
Phonetic Fuzzy Matcher
As mentioned previously, fuzzy matching is used to match new members to their information even if they make typos or use a nickname. This is implemented using the Levenshtein edit distance. Elasticsearch has native support for edit distance fuzzy matching, but only up to a distance of two. We wanted to support searches with larger edit distances, but didn’t want to use the MySQL approach of brute-force filtering all the records by edit distance. We decided to try making a first pass using a phonetic matching filter, which only admits documents which have a phonetic similarity to the search input, and then do a brute force levenshtein filtering over the smaller search space. The assumption underlying this approach is that any typo or nickname that we would be willing to accept must not make the name completely unrecognizable.
Elasticsearch on the ETL
Our ETL stage consists of four steps:
- Use a bash script to pull data from four tables containing recruitable population data, located in our Redshift database
- Use a Python script to assemble that data into JSON documents*
- Create a new index in our Elasticsearch cluster and push up our data in bulk
- Switch the index alias and drop the old index
*Note that we can’t just do JOINs within Redshift because the JSON documents end up having arrays within them
Our ETL stage features a multithreaded bulk indexing system that allows us to push documents to our cluster in batches of 250 on each of 8 threads. The alias swap allows for seamless index switching. Our new ETL stage causes no server-wide downtime and, as of the time of writing, takes just 6.5 minutes to run–a nearly 10x speedup!
From Search Input to Elasticsearch Query
Search operations against our cluster are managed by our Recruitables DAO. To search for a record in our cluster, a caller provides a search input, which is a set of match rules. If a document matches against any of these rules, it is admitted to the solution set. A match rule consists of one or more criteria, all of which need to be satisfied for the document to match the rule. Each match criteria is made up of a field–like first name, last name, or date of birth–a comparison operation–such as equals, starts with, or ends with–and a target value. To create a query string, our API decomposes each match rule into its component criteria, then translates each criteria into the Elasticsearch query language.
As an example, here is a simple search input
First name equals “Jane” AND last name equals “Doe” AND birthdate equals “01/01/2000” OR Last name equals “Doe” AND client equals “LVGO” AND zipcode starts with “1234”
and its corresponding Elasticsearch query JSON
"bool" : { "should" : [ "bool" : { "must": [ {"match" : {"first_name" : "Jane"}}, {"match" : {"last_name" : "Doe"}}, {"match" : {"birth_date" : "01-01-2000"}} ] }, "bool" : { "must": [ {"match" : {"last_name" : "Doe"}}, {"term" : {"client" : "LVGO"}}, {"prefix" : {"zipcode" : "1234"}} ] } ] }
Because our comparison operations are standardized, we are able to construct our Elasticsearch queries without knowing the match rules or criteria to be used in advance. Our API can handle any search input as long as it uses our predefined comparison operations. This separation of usage and implementation makes our API flexible.
The Future of Search at Livongo
Moving forward, we see many ways to optimize Elasticsearch for Recruitables. From a hardware perspective, there is still research to be done on the optimal hardware provisioning and cluster configuration, as well as data routing schema. And, from a data science perspective, we can look deeper into optimizing our index mapping and further reducing our fuzzy matching search space.
The implications of this project for Livongo, however, go far beyond user signups. The speedups we observed in our ETL are an indication of the power of Elasticsearch and its potential to become our primary search engine.
As Livongo grows, we expect increasing demand on our infrastructure. By prototyping early and experimenting with new technology, the tech team can ensure that Livongo maintains the high quality of service that our members and clients have come to expect.
Acknowledgements
This project would not have been possible without the support of Mike Seydel, Morgen Peschke, Andy Xiang, Vivek Ragunathan, Tali Longkumer, Rob Holley, and Michael Iskander.