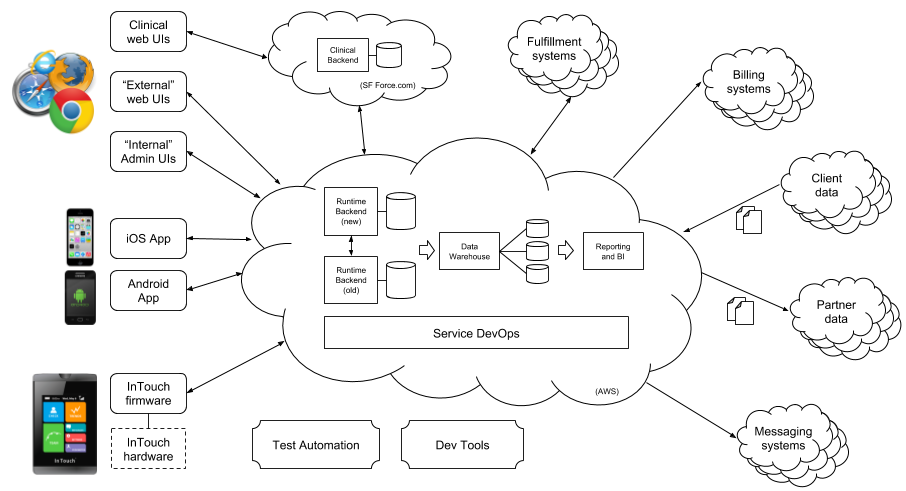
In this post we paint the broad landscape of Livongo’s technology components as illustrated in the high-level picture below. In future posts we’ll drill down into selected areas.
User-Facing Tech
Our user-facing tech is shown on the left side of the diagram. The starting point for Livongo is of course our cellular-connected blood glucose meter, shown in the lower left. This FDA-regulated medical device includes custom firmware written in C++, which can take advantage of the internal ARM processor and color touchscreen to offer a richer experience to the member performing a BG check. The firmware permits Over-the-Air firmware updates through the 3G antenna, which allows us to continually improve the experience and functionality of the device.
We also have rich iOS and Android mobile apps out in their respective app stores. The apps use a mixture of native code and hybrid techniques. On iOS we have a code base that is 70% Swift, 30% objective-C. The iOS tech stack leverages well known frameworks such as AFNetworking, SQLite.swift, Apollo for graphQL endpoints. Similarly the Android stack takes advantage of frameworks such as OkHttp3, greenDAO ORM, EventBus. The clients support offline mode (solid client side caching), integrate with BLE peripherals, support social and Livongo community interactions, content publishing as well as bidirectional user data syncing. We also have a native live chat implemented on top of PubNub’s live data stream socket network.
Lastly we offer multiple responsive web applications. They are compatible with all modern browsers such as: IE, Chrome, Safari, FireFox, and Brave. The web app code stack is composed of 2 main applications: internal vs. external, and it dynamically adapts to each one through environment configurations. We are using AngularJS and JQuery as the web app backbone; additionally, we include some support javascript libraries for a variety of micro web components. One major development effort done on the external web app is the ability to do A/B testing (VWO) and data analysis (Mixpanel). These instruments allows us to make better decisions as well as the flexibility to enable/disable user facing features.
Cloud-Based Backend Tech
For our backend tech we use Scala as our primary development language. We currently run three different sets of API servers, one for our BG meters, one for our partner data-exchange APIs, and one for our core platform APIs.
We use the HL7 FHIR web standard for healthcare interoperability and the open-source HAPI-FHIR Java library for our partner APIs, and we use REST and increasingly GraphQL for our platform APIs. Our InTouch APIs support a legacy RPC-like HTTP protocol for older APIs and REST with protocol buffer payloads for newer APIs. Our InTouch and platform APIs are built on the Play framework.
For API-triggered tasks that don’t have to be completed synchronously during the request (e.g., sending out an email or SMS notification resulting from a BG check), we publish messages to RabbitMQ and run message-driven Scala applications that process them. We also have schedule-driven Scala applications for cron-type jobs (like activating cellular service for a newly provisioned BG meter).
Our APIs and message/schedule-driven services interact with many external systems as illustrated in the diagram, with API interactions happening only when they need to be synchronous with the API call.
We use MySQL and SQL Server (legacy) for our OLTP databases, and a combination of Hadoop/Hive and AWS Redshift for our data warehouse. Our data warehouse is updated nightly using a workflow specified as 29-stage Jenkins Pipeline that uses various scripted tools (e.g. Apache sqoop) and custom SQL transformations to update both the raw and aggregated tables.
We host all of our backend tech on AWS.
Clinician-Facing Tech
Our user-supporting diabetes educators and other clinicians use a rich web-based clinical portal built on salesforce.com. The clinical portal operates off salesforce-hosted databases that are synchronized with Livongo databases using on-demand and batch REST APIs.
Internal Administration Tech
Our internal administration web UI (Galaxy) is built on Bootstrap and Angular. It utilizes our backend REST APIs for customer support and general business flow and management for the nontechnical audience. In addition to being a portal for internal users, it will also incorporate features like RBAC and SSO for governance reasons. While it is still under development, due to the modular nature of the architecture, there are already certain functionalities live. The end-goal for Galaxy is to be a one-stop shop for all of internal users’ needs. Last but not least, the portal is built on the same stack as external-facing Member Portal. This allows us to reuse any tech upgrades and advances, and to keep the architecture consistent for both sites.
Customer/Partner Data Ingestion Tech
For ingesting and synchronizing customer data (e.g., information on employees eligible for Livongo) and partner data (e.g., prescription information for Livongo users), we use a set of homegrown Scala applications that handle automatic data ingestion, parsing, cleanup, normalization, transformation, and filtering on large data sets.
Data Science and Analytics Tech
Data within our Hive and Redshift data warehouses strictly partitions data so that the main data warehouse is restricted to non-personally-identifiable data only. This information is safe for aggregation and correlation for analytical purposes, but can’t be tied back to individual members.
Low-level analyses can be performed using direct SQL queries to these tables, but most employees access standard reports and dashboards updated at the end of the nightly ETL pipeline. Reports are generated using a custom framework, and internal dashboards use Metabase.
Nightly runs of machine learning algorithms are used to improve messaging relevance algorithms and also ranking and prediction for message personalization for members. These TensorFlow-based algorithms run nightly in Jenkins on GPU instances.